2024年欧洲杯预选赛靠谱的体育彩票 | 又打脸!微软用新的指示战略讲解:GPT-4当先于GeminiUltra

著述转载来源:Yangz冰岛足球注册人口
微软思要强调的,亦然 Gemini 发布时就已泄涌现来的,是两个模子的性能其实是杰出的。 图片来源:由无界 AI生成
图片来源:由无界 AI生成几乎不讲武德,继上周推出堪称其“最新、功能最庞大”的 AI 模子 Gemini 后,本日,谷歌文告将向斥地东说念主员和组织提供 Gemini Pro 以及一系列新的东说念主工智能用具、模子和基础架构。
起首,Gemini Pro 可通过 Gemini API 提供给 Google AI Studio(免费的基于 Web 的斥地用具)的斥地东说念主员。企业也不错通过谷歌云的 Vertex AI 平台进期骗用。此外,谷歌还将在 Vertex AI 中引入其他模子,匡助斥地者和企业天真构建和发布应用才智,包括升级版的文生图用具 Imagen 2,以及针对医疗保健行业微调的基础模子系列 MedLM。另外,谷歌还文告其面向斥地东说念主员的在线合作用具 Duet AI 已全面上线。
手脚对 OpenAI GPT-4 的修起,谷歌 DeepMind 称,Gemini 的 Ultra 版块在 32 项圭臬性能想法中,有 30 名想法皆优于 GPT-4。
关系词,发布还不到一天,Gemini 就遭到了质疑,不仅测试圭臬有失偏颇,连效用视频也疑似编订。
皇冠体育源码无独到偶,微软本日发文更是把谷歌的脸打的啪啪响。微软称,GPT-4 与罕见的指示战略相连结,在谈话相接基准 MMLU(掂量大畛域多任务谈话相接才智)中的发达优于谷歌 Gemini Ultra。
微软的反击:复杂指示素养基准性能
据悉,Medprompt 是微软最近推出的一种指示战略,最初是针对医疗挑战而斥地的。不外,微软的商榷东说念主员发现,它也适用于更平凡的应用。
民间游戏网上娱乐博彩
通过使用翻新版的 Medprompt 运行 GPT-4,微软在 MMLU 基准测试中得到了新的技能水平 (SoTA) 分数。阐述陈说,GPT-4 在 MMLU 中的发达达到了 90.10% 的历史新高,越过了 Gemini Ultra 的 90.04%。
皇冠客服飞机:@seo3687注:MMLU 基准测试是一项学问和推理的概述测试。它包含数学、历史、法律、瞎想机科学、工程和医学等 57 个学科畛域的数万个题目。它被合计是谈话模子最蹙迫的基准。
www.crownbettingzonezonezone.com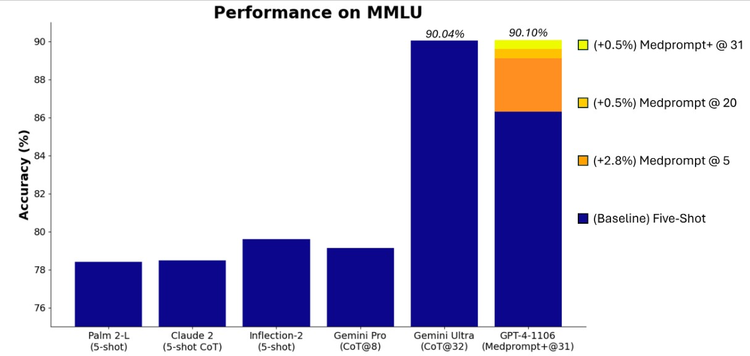
据悉,最初将原始 Medprompt 应用于 GPT-4 在概述 MMLU 上的得分率为 89.1%。而通过将 Medprompt 中的贴近调用次数从 5 次加多到 20 次,GPT-4 在 MMLU 上的发达进一步素养到 89.56%。为了达到新的 SoTA,微软的商榷东说念主员将 Medprompt 推广为 Medprompt+,步骤是在 Medprompt 中添加一种更简单的指示步骤,并制定一种战略,将 Medprompt 基本战略和更简单的指示步骤的谜底连结起来,得出最终谜底。
2024年德国欧洲杯靠谱的体育彩票除了 MMLU 基准测试除外,微软还发布了其他基准测试的戒指,使用这些基准测试中常见的简单指示来炫耀 GPT-4 与 Gemini Ultra 的性能相比。据称,GPT-4 在使用这种测量步骤的多个基准测试中发达均优于 Gemini Ultra,包括 GSM8K、MATH、HumanEval、BIG-Bench-Hard、DROP 和 HellaSwag。
网站以其博彩技巧分享优质博彩服务,广大博彩爱好者提供最佳博彩体验多样化博彩游戏,用户能够博彩游戏中获得乐趣收益。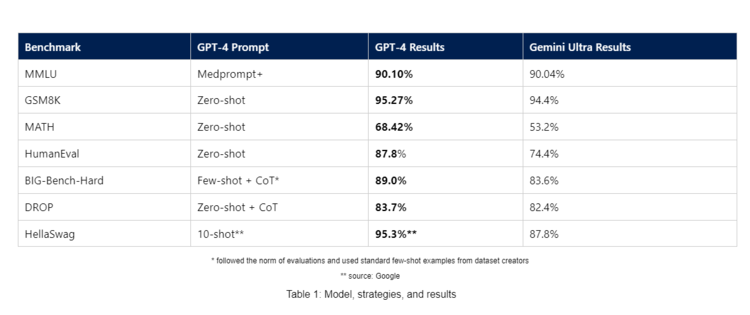
微软示意,诚然系统化的指示工程不错产生最高性能,但其仍在探索使用简单指示的前沿模子开箱即用性能。微软称,蹙迫的是,要热心 GPT-4 的原生功能,以及若何利用零次或一丝指示战略勾通模子。如上图所示,在遴荐更复杂、更昂然的步骤之前,简略单的指示运行有助于缔造基线性能。
2024年欧洲杯预选赛据悉,微软已在名为 Promptbase 的 GitHub 中发布了 Medprompt 和相似的指示战略,包含剧本、通用用具和信息,可匡助重现上述测试戒指。
太阳城tv皇冠官网需要属意的是,在内容应用中,这些基准中的轻捷互异可能不会有太大影响,毕竟它的想法是用来公关的。微软思要强调的,亦然在 Gemini Ultra 发布时就依然泄涌现来的,是两个模子的性能其实是杰出的。
可能正如比尔·盖茨最近所说的那样,面前体式的 LLM 技能依然达到了极限。大略要比及 GPT-4.5 或 GPT-5 的出现,才有可能迎来下一波波澜。
参考相接:
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP